|
PLSSVM - Parallel Least Squares Support Vector Machine
2.0.0
A Least Squares Support Vector Machine implementation using different backends.
|
|
PLSSVM - Parallel Least Squares Support Vector Machine
2.0.0
A Least Squares Support Vector Machine implementation using different backends.
|
A C-SVM implementation using HIP as backend. More...
#include <csvm.hpp>
Public Types | |
| using | device_ptr_type = detail::device_ptr< real_type > |
| The type of the device pointer (dependent on the used backend). | |
| using | queue_type = int |
| The type of the device queue (dependent on the used backend). | |
Public Member Functions | |
| csvm (parameter params={}) | |
Construct a new C-SVM using the HIP backend with the parameters given through params. More... | |
| csvm (target_platform target, parameter params={}) | |
Construct a new C-SVM using the HIP backend on the target platform with the parameters given through params. More... | |
| template<typename... Args, PLSSVM_REQUIRES(::plssvm::detail::has_only_parameter_named_args_v< Args... >) > | |
| csvm (Args &&...named_args) | |
Construct a new C-SVM using the HIP backend and the optionally provided named_args. More... | |
| template<typename... Args, PLSSVM_REQUIRES(::plssvm::detail::has_only_parameter_named_args_v< Args... >) > | |
| csvm (const target_platform target, Args &&...named_args) | |
Construct a new C-SVM using the HIP backend on the target platform and the optionally provided named_args. More... | |
| csvm (const csvm &)=delete | |
| Delete copy-constructor since a CSVM is a move-only type. More... | |
| csvm (csvm &&) noexcept=default | |
| Default move-constructor since a virtual destructor has been declared. noexcept More... | |
| csvm & | operator= (const csvm &)=delete |
| Delete copy-assignment operator since a CSVM is a move-only type. More... | |
| csvm & | operator= (csvm &&) noexcept=default |
| Default move-assignment operator since a virtual destructor has been declared. noexcept More... | |
| ~csvm () override | |
| Wait for all operations on all HIP devices to finish. More... | |
| std::size_t | num_available_devices () const noexcept |
| Return the number of available devices for the current backend. More... | |
| target_platform | get_target_platform () const noexcept |
| Return the target platform (i.e, CPU or GPU including the vendor) this SVM runs on. More... | |
| parameter | get_params () const noexcept |
| Return the currently used SVM parameter. More... | |
| void | set_params (parameter params) noexcept |
Override the old SVM parameter with the new plssvm::parameter params. More... | |
| template<typename... Args, PLSSVM_REQUIRES(detail::has_only_parameter_named_args_v< Args... >) > | |
| void | set_params (Args &&...named_args) |
Override the old SVM parameter with the new ones given as named parameters in named_args. More... | |
| template<typename real_type , typename label_type , typename... Args> | |
| model< real_type, label_type > | fit (const data_set< real_type, label_type > &data, Args &&...named_args) const |
Fit a model using the current SVM on the data. More... | |
| template<typename real_type , typename label_type > | |
| std::vector< label_type > | predict (const model< real_type, label_type > &model, const data_set< real_type, label_type > &data) const |
Predict the labels for the data set using the model. More... | |
| template<typename real_type , typename label_type > | |
| real_type | score (const model< real_type, label_type > &model) const |
Calculate the accuracy of the model. More... | |
| template<typename real_type , typename label_type > | |
| real_type | score (const model< real_type, label_type > &model, const data_set< real_type, label_type > &data) const |
Calculate the accuracy of the labeled data set using the model. More... | |
Protected Types | |
| using | base_type = ::plssvm::detail::gpu_csvm< detail::device_ptr, int > |
| The template base type of the HIP C-SVM class. | |
Protected Member Functions | |
| void | device_synchronize (const queue_type &queue) const final |
Synchronize the device denoted by queue. More... | |
| void | run_q_kernel (std::size_t device, const ::plssvm::detail::execution_range &range, const ::plssvm::detail::parameter< float > ¶ms, device_ptr_type< float > &q_d, const device_ptr_type< float > &data_d, const device_ptr_type< float > &data_last_d, std::size_t num_data_points_padded, std::size_t num_features) const final |
Run the device kernel filling the q vector. More... | |
| void | run_q_kernel (std::size_t device, const ::plssvm::detail::execution_range &range, const ::plssvm::detail::parameter< double > ¶ms, device_ptr_type< double > &q_d, const device_ptr_type< double > &data_d, const device_ptr_type< double > &data_last_d, std::size_t num_data_points_padded, std::size_t num_features) const final |
Run the device kernel filling the q vector. More... | |
| template<typename real_type > | |
| void | run_q_kernel_impl (std::size_t device, const ::plssvm::detail::execution_range &range, const ::plssvm::detail::parameter< real_type > ¶ms, device_ptr_type< real_type > &q_d, const device_ptr_type< real_type > &data_d, const device_ptr_type< real_type > &data_last_d, std::size_t num_data_points_padded, std::size_t num_features) const |
Run the device kernel filling the q vector. More... | |
| void | run_svm_kernel (std::size_t device, const ::plssvm::detail::execution_range &range, const ::plssvm::detail::parameter< float > ¶ms, const device_ptr_type< float > &q_d, device_ptr_type< float > &r_d, const device_ptr_type< float > &x_d, const device_ptr_type< float > &data_d, float QA_cost, float add, std::size_t num_data_points_padded, std::size_t num_features) const final |
| Run the main device kernel used in the CG algorithm. More... | |
| void | run_svm_kernel (std::size_t device, const ::plssvm::detail::execution_range &range, const ::plssvm::detail::parameter< double > ¶ms, const device_ptr_type< double > &q_d, device_ptr_type< double > &r_d, const device_ptr_type< double > &x_d, const device_ptr_type< double > &data_d, double QA_cost, double add, std::size_t num_data_points_padded, std::size_t num_features) const final |
| Run the main device kernel used in the CG algorithm. More... | |
| template<typename real_type > | |
| void | run_svm_kernel_impl (std::size_t device, const ::plssvm::detail::execution_range &range, const ::plssvm::detail::parameter< real_type > ¶ms, const device_ptr_type< real_type > &q_d, device_ptr_type< real_type > &r_d, const device_ptr_type< real_type > &x_d, const device_ptr_type< real_type > &data_d, real_type QA_cost, real_type add, std::size_t num_data_points_padded, std::size_t num_features) const |
| Run the main device kernel used in the CG algorithm. More... | |
| void | run_w_kernel (std::size_t device, const ::plssvm::detail::execution_range &range, device_ptr_type< float > &w_d, const device_ptr_type< float > &alpha_d, const device_ptr_type< float > &data_d, const device_ptr_type< float > &data_last_d, std::size_t num_data_points, std::size_t num_features) const final |
Run the device kernel the calculate the w vector used to speed up the prediction when using the linear kernel function. More... | |
| void | run_w_kernel (std::size_t device, const ::plssvm::detail::execution_range &range, device_ptr_type< double > &w_d, const device_ptr_type< double > &alpha_d, const device_ptr_type< double > &data_d, const device_ptr_type< double > &data_last_d, std::size_t num_data_points, std::size_t num_features) const final |
Run the device kernel the calculate the w vector used to speed up the prediction when using the linear kernel function. More... | |
| template<typename real_type > | |
| void | run_w_kernel_impl (std::size_t device, const ::plssvm::detail::execution_range &range, device_ptr_type< real_type > &w_d, const device_ptr_type< real_type > &alpha_d, const device_ptr_type< real_type > &data_d, const device_ptr_type< real_type > &data_last_d, std::size_t num_data_points, std::size_t num_features) const |
Run the device kernel the calculate the w vector used to speed up the prediction when using the linear kernel function. More... | |
| void | run_predict_kernel (const ::plssvm::detail::execution_range &range, const ::plssvm::detail::parameter< float > ¶ms, device_ptr_type< float > &out_d, const device_ptr_type< float > &alpha_d, const device_ptr_type< float > &point_d, const device_ptr_type< float > &data_d, const device_ptr_type< float > &data_last_d, std::size_t num_support_vectors, std::size_t num_predict_points, std::size_t num_features) const final |
Run the device kernel (only on the first device) to predict the new data points point_d. More... | |
| void | run_predict_kernel (const ::plssvm::detail::execution_range &range, const ::plssvm::detail::parameter< double > ¶ms, device_ptr_type< double > &out_d, const device_ptr_type< double > &alpha_d, const device_ptr_type< double > &point_d, const device_ptr_type< double > &data_d, const device_ptr_type< double > &data_last_d, std::size_t num_support_vectors, std::size_t num_predict_points, std::size_t num_features) const final |
Run the device kernel (only on the first device) to predict the new data points point_d. More... | |
| template<typename real_type > | |
| void | run_predict_kernel_impl (const ::plssvm::detail::execution_range &range, const ::plssvm::detail::parameter< real_type > ¶ms, device_ptr_type< real_type > &out_d, const device_ptr_type< real_type > &alpha_d, const device_ptr_type< real_type > &point_d, const device_ptr_type< real_type > &data_d, const device_ptr_type< real_type > &data_last_d, std::size_t num_support_vectors, std::size_t num_predict_points, std::size_t num_features) const |
Run the device kernel (only on the first device) to predict the new data points point_d. More... | |
| std::pair< std::vector< float >, float > | solve_system_of_linear_equations (const parameter< float > ¶ms, const std::vector< std::vector< float >> &A, std::vector< float > b, float eps, unsigned long long max_iter) const final |
| Solves the equation \(Ax = b\) using the Conjugated Gradients algorithm. More... | |
| std::pair< std::vector< double >, double > | solve_system_of_linear_equations (const parameter< double > ¶ms, const std::vector< std::vector< double >> &A, std::vector< double > b, double eps, unsigned long long max_iter) const final |
| Solves the equation \(Ax = b\) using the Conjugated Gradients algorithm. More... | |
| std::pair< std::vector< real_type >, real_type > | solve_system_of_linear_equations_impl (const parameter< real_type > ¶ms, const std::vector< std::vector< real_type >> &A, std::vector< real_type > b, real_type eps, unsigned long long max_iter) const |
| Solves the equation \(Ax = b\) using the Conjugated Gradients algorithm. More... | |
| std::vector< float > | predict_values (const parameter< float > ¶ms, const std::vector< std::vector< float >> &support_vectors, const std::vector< float > &alpha, float rho, std::vector< float > &w, const std::vector< std::vector< float >> &predict_points) const final |
| Uses the already learned model to predict the class of multiple (new) data points. More... | |
| std::vector< double > | predict_values (const parameter< double > ¶ms, const std::vector< std::vector< double >> &support_vectors, const std::vector< double > &alpha, double rho, std::vector< double > &w, const std::vector< std::vector< double >> &predict_points) const final |
| Uses the already learned model to predict the class of multiple (new) data points. More... | |
| std::vector< real_type > | predict_values_impl (const parameter< real_type > ¶ms, const std::vector< std::vector< real_type >> &support_vectors, const std::vector< real_type > &alpha, real_type rho, std::vector< real_type > &w, const std::vector< std::vector< real_type >> &predict_points) const |
| Uses the already learned model to predict the class of multiple (new) data points. More... | |
| std::size_t | select_num_used_devices (kernel_function_type kernel, std::size_t num_features) const noexcept |
Returns the number of usable devices given the kernel function kernel and the number of features num_features. More... | |
| std::tuple< std::vector< device_ptr_type< real_type > >, std::vector< device_ptr_type< real_type > >, std::vector< std::size_t > > | setup_data_on_device (const std::vector< std::vector< real_type >> &data, std::size_t num_data_points_to_setup, std::size_t num_features_to_setup, std::size_t boundary_size, std::size_t num_used_devices) const |
| Performs all necessary steps such that the data is available on the device with the correct layout. More... | |
| std::vector< real_type > | generate_q (const parameter< real_type > ¶ms, const std::vector< device_ptr_type< real_type >> &data_d, const std::vector< device_ptr_type< real_type >> &data_last_d, std::size_t num_data_points, const std::vector< std::size_t > &feature_ranges, std::size_t boundary_size) const |
Calculate the q vector used in the dimensional reduction. More... | |
| std::vector< real_type > | calculate_w (const std::vector< device_ptr_type< real_type >> &data_d, const std::vector< device_ptr_type< real_type >> &data_last_d, const std::vector< device_ptr_type< real_type >> &alpha_d, std::size_t num_data_points, const std::vector< std::size_t > &feature_ranges) const |
Precalculate the w vector to speedup up the prediction using the linear kernel function. More... | |
| void | run_device_kernel (std::size_t device, const parameter< real_type > ¶ms, const device_ptr_type< real_type > &q_d, device_ptr_type< real_type > &r_d, const device_ptr_type< real_type > &x_d, const device_ptr_type< real_type > &data_d, const std::vector< std::size_t > &feature_ranges, real_type QA_cost, real_type add, std::size_t dept, std::size_t boundary_size) const |
Select the correct kernel based on the value of kernel_ and run it on the device denoted by device. More... | |
| void | device_reduction (std::vector< device_ptr_type< real_type >> &buffer_d, std::vector< real_type > &buffer) const |
Combines the data in buffer_d from all devices into buffer and distributes them back to each device. More... | |
| virtual void | run_q_kernel (std::size_t device, const detail::execution_range &range, const parameter< float > ¶ms, device_ptr_type< float > &q_d, const device_ptr_type< float > &data_d, const device_ptr_type< float > &data_last_d, std::size_t num_data_points_padded, std::size_t num_features) const=0 |
Run the device kernel filling the q vector. More... | |
| virtual void | run_q_kernel (std::size_t device, const detail::execution_range &range, const parameter< double > ¶ms, device_ptr_type< double > &q_d, const device_ptr_type< double > &data_d, const device_ptr_type< double > &data_last_d, std::size_t num_data_points_padded, std::size_t num_features) const=0 |
Run the device kernel filling the q vector. More... | |
| virtual void | run_svm_kernel (std::size_t device, const detail::execution_range &range, const parameter< float > ¶ms, const device_ptr_type< float > &q_d, device_ptr_type< float > &r_d, const device_ptr_type< float > &x_d, const device_ptr_type< float > &data_d, float QA_cost, float add, std::size_t num_data_points_padded, std::size_t num_features) const=0 |
| Run the main device kernel used in the CG algorithm. More... | |
| virtual void | run_svm_kernel (std::size_t device, const detail::execution_range &range, const parameter< double > ¶ms, const device_ptr_type< double > &q_d, device_ptr_type< double > &r_d, const device_ptr_type< double > &x_d, const device_ptr_type< double > &data_d, double QA_cost, double add, std::size_t num_data_points_padded, std::size_t num_features) const=0 |
| Run the main device kernel used in the CG algorithm. More... | |
| virtual void | run_w_kernel (std::size_t device, const detail::execution_range &range, device_ptr_type< float > &w_d, const device_ptr_type< float > &alpha_d, const device_ptr_type< float > &data_d, const device_ptr_type< float > &data_last_d, std::size_t num_data_points, std::size_t num_features) const=0 |
Run the device kernel the calculate the w vector used to speed up the prediction when using the linear kernel function. More... | |
| virtual void | run_w_kernel (std::size_t device, const detail::execution_range &range, device_ptr_type< double > &w_d, const device_ptr_type< double > &alpha_d, const device_ptr_type< double > &data_d, const device_ptr_type< double > &data_last_d, std::size_t num_data_points, std::size_t num_features) const=0 |
Run the device kernel the calculate the w vector used to speed up the prediction when using the linear kernel function. More... | |
| virtual void | run_predict_kernel (const detail::execution_range &range, const parameter< float > ¶ms, device_ptr_type< float > &out_d, const device_ptr_type< float > &alpha_d, const device_ptr_type< float > &point_d, const device_ptr_type< float > &data_d, const device_ptr_type< float > &data_last_d, std::size_t num_support_vectors, std::size_t num_predict_points, std::size_t num_features) const=0 |
Run the device kernel (only on the first device) to predict the new data points point_d. More... | |
| virtual void | run_predict_kernel (const detail::execution_range &range, const parameter< double > ¶ms, device_ptr_type< double > &out_d, const device_ptr_type< double > &alpha_d, const device_ptr_type< double > &point_d, const device_ptr_type< double > &data_d, const device_ptr_type< double > &data_last_d, std::size_t num_support_vectors, std::size_t num_predict_points, std::size_t num_features) const=0 |
Run the device kernel (only on the first device) to predict the new data points point_d. More... | |
Protected Attributes | |
| std::vector< queue_type > | devices_ |
| The available/used backend devices. | |
| target_platform | target_ { plssvm::target_platform::automatic } |
| The target platform of this SVM. | |
Private Member Functions | |
| void | init (target_platform target) |
| Initialize all important states related to the HIP backend. More... | |
| void | sanity_check_parameter () const |
| Perform some sanity checks on the passed SVM parameters. More... | |
Private Attributes | |
| parameter | params_ {} |
| The SVM parameter (e.g., cost, degree, gamma, coef0) currently in use. | |
A C-SVM implementation using HIP as backend.
|
explicit |
Construct a new C-SVM using the HIP backend with the parameters given through params.
Currently only tested with AMD GPUs.
| [in] | params | struct encapsulating all possible parameters |
| plssvm::exception | all exceptions thrown in the base class constructor |
| plssvm::hip::backend_exception | if the target platform isn't plssvm::target_platform::automatic or plssvm::target_platform::gpu_amd |
| plssvm::hip::backend_exception | if the plssvm::target_platform::gpu_amd target isn't available |
| plssvm::hip::backend_exception | if no HIP capable devices could be found |
|
explicit |
Construct a new C-SVM using the HIP backend on the target platform with the parameters given through params.
Currently only tested with AMD GPUs.
| [in] | target | the target platform used for this C-SVM |
| [in] | params | struct encapsulating all possible SVM parameters |
| plssvm::exception | all exceptions thrown in the base class constructor |
| plssvm::hip::backend_exception | if the target platform isn't plssvm::target_platform::automatic or plssvm::target_platform::gpu_amd |
| plssvm::hip::backend_exception | if the plssvm::target_platform::gpu_amd target isn't available |
| plssvm::hip::backend_exception | if no HIP capable devices could be found |
|
inlineexplicit |
Construct a new C-SVM using the HIP backend and the optionally provided named_args.
Currently only tested with AMD GPUs.
| [in] | named_args | the additional optional named-parameter |
| plssvm::exception | all exceptions thrown in the base class constructor |
| plssvm::hip::backend_exception | if the target platform isn't plssvm::target_platform::automatic or plssvm::target_platform::gpu_amd |
| plssvm::hip::backend_exception | if the plssvm::target_platform::gpu_amd target isn't available |
| plssvm::hip::backend_exception | if no HIP capable devices could be found |
|
inlineexplicit |
Construct a new C-SVM using the HIP backend on the target platform and the optionally provided named_args.
Currently only tested with AMD GPUs.
| [in] | target | the target platform used for this C-SVM |
| [in] | named_args | the additional optional named-parameter |
| plssvm::exception | all exceptions thrown in the base class constructor |
| plssvm::hip::backend_exception | if the target platform isn't plssvm::target_platform::automatic or plssvm::target_platform::gpu_amd |
| plssvm::hip::backend_exception | if the plssvm::target_platform::gpu_amd target isn't available |
| plssvm::hip::backend_exception | if no HIP capable devices could be found |
|
delete |
Delete copy-constructor since a CSVM is a move-only type.
|
defaultnoexcept |
Default move-constructor since a virtual destructor has been declared. noexcept
noexcept
|
overridevirtual |
Wait for all operations on all HIP devices to finish.
Terminates the program, if any exception is thrown.
Reimplemented from plssvm::csvm.
Delete copy-assignment operator since a CSVM is a move-only type.
*this Default move-assignment operator since a virtual destructor has been declared. noexcept
*this noexcept
|
finalprotectedvirtual |
Synchronize the device denoted by queue.
| [in] | queue | the queue denoting the device to synchronize |
Implements plssvm::detail::gpu_csvm< detail::device_ptr, int >.
|
inlinefinalprotected |
Run the device kernel filling the q vector.
| [in] | device | the device ID denoting the GPU on which the kernel should be executed |
| [in] | range | the execution range used to launch the kernel |
| [in] | params | the SVM parameter used (e.g., kernel_type) |
| [out] | q_d | the q vector to fill located on the device(s) |
| [in] | data_d | the data points used in the dimensional reduction located on the device(s) |
| [in] | data_last_d | the last data point of the data set located on the device(s) |
| [in] | num_data_points_padded | the number of data points after the padding has been applied |
| [in] | num_features | number of features used for the calculation on the device |
|
inlinefinalprotected |
Run the device kernel filling the q vector.
| [in] | device | the device ID denoting the GPU on which the kernel should be executed |
| [in] | range | the execution range used to launch the kernel |
| [in] | params | the SVM parameter used (e.g., kernel_type) |
| [out] | q_d | the q vector to fill located on the device(s) |
| [in] | data_d | the data points used in the dimensional reduction located on the device(s) |
| [in] | data_last_d | the last data point of the data set located on the device(s) |
| [in] | num_data_points_padded | the number of data points after the padding has been applied |
| [in] | num_features | number of features used for the calculation on the device |
|
protected |
Run the device kernel filling the q vector.
| [in] | device | the device ID denoting the GPU on which the kernel should be executed |
| [in] | range | the execution range used to launch the kernel |
| [in] | params | the SVM parameter used (e.g., kernel_type) |
| [out] | q_d | the q vector to fill located on the device(s) |
| [in] | data_d | the data points used in the dimensional reduction located on the device(s) |
| [in] | data_last_d | the last data point of the data set located on the device(s) |
| [in] | num_data_points_padded | the number of data points after the padding has been applied |
| [in] | num_features | number of features used for the calculation on the device |
|
inlinefinalprotected |
Run the main device kernel used in the CG algorithm.
| [in] | device | the device ID denoting the GPU on which the kernel should be executed |
| [in] | range | the execution range used to launch the kernel |
| [in] | params | the SVM parameter used (e.g., kernel_type) |
| [in] | q_d | the q vector located on the device(s) |
| [in,out] | r_d | the result vector located on the device(s) |
| [in] | x_d | the right-hand side of the equation located on the device(s) |
| [in] | data_d | the data points used in the dimensional reduction located on the device(s) |
| [in] | add | denotes whether the values are added or subtracted from the result vector |
| [in] | QA_cost | a value used in the dimensional reduction |
| [in] | num_data_points_padded | the number of data points after the padding has been applied |
| [in] | num_features | number of features used for the calculation in the device |
|
inlinefinalprotected |
Run the main device kernel used in the CG algorithm.
| [in] | device | the device ID denoting the GPU on which the kernel should be executed |
| [in] | range | the execution range used to launch the kernel |
| [in] | params | the SVM parameter used (e.g., kernel_type) |
| [in] | q_d | the q vector located on the device(s) |
| [in,out] | r_d | the result vector located on the device(s) |
| [in] | x_d | the right-hand side of the equation located on the device(s) |
| [in] | data_d | the data points used in the dimensional reduction located on the device(s) |
| [in] | add | denotes whether the values are added or subtracted from the result vector |
| [in] | QA_cost | a value used in the dimensional reduction |
| [in] | num_data_points_padded | the number of data points after the padding has been applied |
| [in] | num_features | number of features used for the calculation in the device |
|
protected |
Run the main device kernel used in the CG algorithm.
| [in] | device | the device ID denoting the GPU on which the kernel should be executed |
| [in] | range | the execution range used to launch the kernel |
| [in] | params | the SVM parameter used (e.g., kernel_type) |
| [in] | q_d | the q vector located on the device(s) |
| [in,out] | r_d | the result vector located on the device(s) |
| [in] | x_d | the right-hand side of the equation located on the device(s) |
| [in] | data_d | the data points used in the dimensional reduction located on the device(s) |
| [in] | add | denotes whether the values are added or subtracted from the result vector |
| [in] | QA_cost | a value used in the dimensional reduction |
| [in] | num_data_points_padded | the number of data points after the padding has been applied |
| [in] | num_features | number of features used for the calculation in the device |
|
inlinefinalprotected |
Run the device kernel the calculate the w vector used to speed up the prediction when using the linear kernel function.
| [in] | device | the device ID denoting the device on which the kernel should be executed |
| [in] | range | the execution range used to launch the |
| [out] | w_d | the w vector to fill, used to speed up the prediction when using the linear kernel located on the device(s) |
| [in] | alpha_d | the previously calculated weight for each data point located on the device(s) |
| [in] | data_d | the data points used in the dimensional reduction located on the device(s) |
| [in] | data_last_d | the last data point of the data set located on the device(s) |
| [in] | num_data_points | the number of data points |
| [in] | num_features | number of features used for the calculation on the device |
|
inlinefinalprotected |
Run the device kernel the calculate the w vector used to speed up the prediction when using the linear kernel function.
| [in] | device | the device ID denoting the device on which the kernel should be executed |
| [in] | range | the execution range used to launch the |
| [out] | w_d | the w vector to fill, used to speed up the prediction when using the linear kernel located on the device(s) |
| [in] | alpha_d | the previously calculated weight for each data point located on the device(s) |
| [in] | data_d | the data points used in the dimensional reduction located on the device(s) |
| [in] | data_last_d | the last data point of the data set located on the device(s) |
| [in] | num_data_points | the number of data points |
| [in] | num_features | number of features used for the calculation on the device |
|
protected |
Run the device kernel the calculate the w vector used to speed up the prediction when using the linear kernel function.
| [in] | device | the device ID denoting the device on which the kernel should be executed |
| [in] | range | the execution range used to launch the |
| [out] | w_d | the w vector to fill, used to speed up the prediction when using the linear kernel located on the device(s) |
| [in] | alpha_d | the previously calculated weight for each data point located on the device(s) |
| [in] | data_d | the data points used in the dimensional reduction located on the device(s) |
| [in] | data_last_d | the last data point of the data set located on the device(s) |
| [in] | num_data_points | the number of data points |
| [in] | num_features | number of features used for the calculation on the device |
|
inlinefinalprotected |
Run the device kernel (only on the first device) to predict the new data points point_d.
| [in] | range | the execution range used to launch the kernel |
| [in] | params | the SVM parameter used (e.g., kernel_type) |
| [out] | out_d | the calculated prediction |
| [in] | alpha_d | the previously calculated weight for each data point located on the device(s) |
| [in] | point_d | the data points to predict located on the device(s) |
| [in] | data_d | the data points used in the dimensional reduction located on the device(s) |
| [in] | data_last_d | the last data point of the data set located on the device(s) |
| [in] | num_support_vectors | the number of support vectors |
| [in] | num_predict_points | the number of data points to predict |
| [in] | num_features | number of features used for the calculation on the device |
|
inlinefinalprotected |
Run the device kernel (only on the first device) to predict the new data points point_d.
| [in] | range | the execution range used to launch the kernel |
| [in] | params | the SVM parameter used (e.g., kernel_type) |
| [out] | out_d | the calculated prediction |
| [in] | alpha_d | the previously calculated weight for each data point located on the device(s) |
| [in] | point_d | the data points to predict located on the device(s) |
| [in] | data_d | the data points used in the dimensional reduction located on the device(s) |
| [in] | data_last_d | the last data point of the data set located on the device(s) |
| [in] | num_support_vectors | the number of support vectors |
| [in] | num_predict_points | the number of data points to predict |
| [in] | num_features | number of features used for the calculation on the device |
|
protected |
Run the device kernel (only on the first device) to predict the new data points point_d.
| [in] | range | the execution range used to launch the kernel |
| [in] | params | the SVM parameter used (e.g., kernel_type) |
| [out] | out_d | the calculated prediction |
| [in] | alpha_d | the previously calculated weight for each data point located on the device(s) |
| [in] | point_d | the data points to predict located on the device(s) |
| [in] | data_d | the data points used in the dimensional reduction located on the device(s) |
| [in] | data_last_d | the last data point of the data set located on the device(s) |
| [in] | num_support_vectors | the number of support vectors |
| [in] | num_predict_points | the number of data points to predict |
| [in] | num_features | number of features used for the calculation on the device |
|
private |
Initialize all important states related to the HIP backend.
| [in] | target | the target platform to use |
| plssvm::hip::backend_exception | if the target platform isn't plssvm::target_platform::automatic or plssvm::target_platform::gpu_amd |
| plssvm::hip::backend_exception | if the plssvm::target_platform::gpu_amd target isn't available |
| plssvm::hip::backend_exception | if no HIP capable devices could be found |
|
inlinenoexceptinherited |
Return the number of available devices for the current backend.
[[nodiscard]])
|
inlinefinalprotectedvirtualinherited |
Solves the equation \(Ax = b\) using the Conjugated Gradients algorithm.
Uses a slightly modified version of the CG algorithm described by Jonathan Richard Shewchuk:
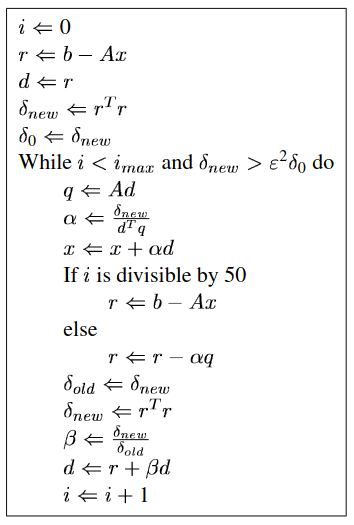
| [in] | params | the SVM parameters used in the respective kernel functions |
| [in] | A | the matrix of the equation \(Ax = b\) (symmetric positive definite) |
| [in] | b | the right-hand side of the equation \(Ax = b\) |
| [in] | eps | the error tolerance |
| [in] | max_iter | the maximum number of CG iterations |
| plssvm::exception | any exception thrown by the backend's implementation |
[[nodiscard]]) Implements plssvm::csvm.
|
inlinefinalprotectedvirtualinherited |
Solves the equation \(Ax = b\) using the Conjugated Gradients algorithm.
Uses a slightly modified version of the CG algorithm described by Jonathan Richard Shewchuk:
| [in] | params | the SVM parameters used in the respective kernel functions |
| [in] | A | the matrix of the equation \(Ax = b\) (symmetric positive definite) |
| [in] | b | the right-hand side of the equation \(Ax = b\) |
| [in] | eps | the error tolerance |
| [in] | max_iter | the maximum number of CG iterations |
| plssvm::exception | any exception thrown by the backend's implementation |
[[nodiscard]]) Implements plssvm::csvm.
|
protectedinherited |
Solves the equation \(Ax = b\) using the Conjugated Gradients algorithm.
Uses a slightly modified version of the CG algorithm described by Jonathan Richard Shewchuk:
| [in] | params | the SVM parameters used in the respective kernel functions |
| [in] | A | the matrix of the equation \(Ax = b\) (symmetric positive definite) |
| [in] | b | the right-hand side of the equation \(Ax = b\) |
| [in] | eps | the error tolerance |
| [in] | max_iter | the maximum number of CG iterations |
| plssvm::exception | any exception thrown by the backend's implementation |
[[nodiscard]])
|
inlinefinalprotectedvirtualinherited |
Uses the already learned model to predict the class of multiple (new) data points.
| [in] | params | the SVM parameters used in the respective kernel functions |
| [in] | support_vectors | the previously learned support vectors |
| [in] | alpha | the alpha values (weights) associated with the support vectors |
| [in] | rho | the rho value determined after training the model |
| [in,out] | w | the normal vector to speedup prediction in case of the linear kernel function, an empty vector in case of the polynomial or rbf kernel |
| [in] | predict_points | the points to predict |
| plssvm::exception | any exception thrown by the backend's implementation |
[[nodiscard]]) Implements plssvm::csvm.
|
inlinefinalprotectedvirtualinherited |
Uses the already learned model to predict the class of multiple (new) data points.
| [in] | params | the SVM parameters used in the respective kernel functions |
| [in] | support_vectors | the previously learned support vectors |
| [in] | alpha | the alpha values (weights) associated with the support vectors |
| [in] | rho | the rho value determined after training the model |
| [in,out] | w | the normal vector to speedup prediction in case of the linear kernel function, an empty vector in case of the polynomial or rbf kernel |
| [in] | predict_points | the points to predict |
| plssvm::exception | any exception thrown by the backend's implementation |
[[nodiscard]]) Implements plssvm::csvm.
|
protectedinherited |
Uses the already learned model to predict the class of multiple (new) data points.
| [in] | params | the SVM parameters used in the respective kernel functions |
| [in] | support_vectors | the previously learned support vectors |
| [in] | alpha | the alpha values (weights) associated with the support vectors |
| [in] | rho | the rho value determined after training the model |
| [in,out] | w | the normal vector to speedup prediction in case of the linear kernel function, an empty vector in case of the polynomial or rbf kernel |
| [in] | predict_points | the points to predict |
| plssvm::exception | any exception thrown by the backend's implementation |
[[nodiscard]])
|
protectednoexceptinherited |
Returns the number of usable devices given the kernel function kernel and the number of features num_features.
Only the linear kernel supports multi-GPU execution, i.e., for the polynomial and rbf kernel, this function always returns 1. In addition, at most num_features devices may be used (i.e., if more devices than features are present not all devices are used).
| [in] | kernel | the kernel function type |
| [in] | num_features | the number of features |
[[nodiscard]])
|
protectedinherited |
Performs all necessary steps such that the data is available on the device with the correct layout.
Distributed the data evenly across all devices, adds padding data points, and transforms the data layout to SoA.
| real_type | the type of the data points (either float or double) |
| [in] | data | the data that should be copied to the device(s) |
| [in] | num_data_points_to_setup | the number of data points that should be copied to the device |
| [in] | num_features_to_setup | the number of features in the data set |
| [in] | boundary_size | the size of the padding boundary |
| [in] | num_used_devices | the number of devices to distribute the data across |
[[nodiscard]])
|
protectedinherited |
Calculate the q vector used in the dimensional reduction.
| real_type | the type of the data points (either float or double) |
| [in] | params | the SVM parameter used to calculate q (e.g., kernel_type) |
| [in] | data_d | the data points used in the dimensional reduction located on the device(s) |
| [in] | data_last_d | the last data point of the data set located on the device(s) |
| [in] | num_data_points | the number of data points in data_p |
| [in] | feature_ranges | the range of features a specific device is responsible for |
| [in] | boundary_size | the size of the padding boundary |
q vector ([[nodiscard]])
|
protectedinherited |
Precalculate the w vector to speedup up the prediction using the linear kernel function.
| real_type | the type of the data points (either float or double) |
| [in] | data_d | the data points used in the dimensional reduction located on the device(s) |
| [in] | data_last_d | the last data point of the data set located on the device(s) |
| [in] | alpha_d | the previously learned weights located on the device(s) |
| [in] | num_data_points | the number of data points in data_p |
| [in] | feature_ranges | the range of features a specific device is responsible for |
w vector ([[nodiscard]])
|
protectedinherited |
Select the correct kernel based on the value of kernel_ and run it on the device denoted by device.
| [in] | device | the device ID denoting the device on which the kernel should be executed |
| [in] | params | the SVM parameter used (e.g., kernel_type) |
| [in] | q_d | subvector of the least-squares matrix equation located on the device(s) |
| [in,out] | r_d | the result vector located on the device(s) |
| [in] | x_d | the right-hand side of the equation located on the device(s) |
| [in] | data_d | the data points used in the dimensional reduction located on the device(s) |
| [in] | feature_ranges | the range of features a specific device is responsible for |
| [in] | QA_cost | a value used in the dimensional reduction |
| [in] | add | denotes whether the values are added or subtracted from the result vector |
| [in] | dept | the number of data points after the dimensional reduction |
| [in] | boundary_size | the size of the padding boundary |
|
protectedinherited |
Combines the data in buffer_d from all devices into buffer and distributes them back to each device.
| [in,out] | buffer_d | the data to gather |
| [in,out] | buffer | the reduced data |
|
protectedpure virtualinherited |
Run the device kernel filling the q vector.
| [in] | device | the device ID denoting the GPU on which the kernel should be executed |
| [in] | range | the execution range used to launch the kernel |
| [in] | params | the SVM parameter used (e.g., kernel_type) |
| [out] | q_d | the q vector to fill located on the device(s) |
| [in] | data_d | the data points used in the dimensional reduction located on the device(s) |
| [in] | data_last_d | the last data point of the data set located on the device(s) |
| [in] | num_data_points_padded | the number of data points after the padding has been applied |
| [in] | num_features | number of features used for the calculation on the device |
|
protectedpure virtualinherited |
Run the device kernel filling the q vector.
| [in] | device | the device ID denoting the GPU on which the kernel should be executed |
| [in] | range | the execution range used to launch the kernel |
| [in] | params | the SVM parameter used (e.g., kernel_type) |
| [out] | q_d | the q vector to fill located on the device(s) |
| [in] | data_d | the data points used in the dimensional reduction located on the device(s) |
| [in] | data_last_d | the last data point of the data set located on the device(s) |
| [in] | num_data_points_padded | the number of data points after the padding has been applied |
| [in] | num_features | number of features used for the calculation on the device |
|
protectedpure virtualinherited |
Run the main device kernel used in the CG algorithm.
| [in] | device | the device ID denoting the GPU on which the kernel should be executed |
| [in] | range | the execution range used to launch the kernel |
| [in] | params | the SVM parameter used (e.g., kernel_type) |
| [in] | q_d | the q vector located on the device(s) |
| [in,out] | r_d | the result vector located on the device(s) |
| [in] | x_d | the right-hand side of the equation located on the device(s) |
| [in] | data_d | the data points used in the dimensional reduction located on the device(s) |
| [in] | add | denotes whether the values are added or subtracted from the result vector |
| [in] | QA_cost | a value used in the dimensional reduction |
| [in] | num_data_points_padded | the number of data points after the padding has been applied |
| [in] | num_features | number of features used for the calculation in the device |
|
protectedpure virtualinherited |
Run the main device kernel used in the CG algorithm.
| [in] | device | the device ID denoting the GPU on which the kernel should be executed |
| [in] | range | the execution range used to launch the kernel |
| [in] | params | the SVM parameter used (e.g., kernel_type) |
| [in] | q_d | the q vector located on the device(s) |
| [in,out] | r_d | the result vector located on the device(s) |
| [in] | x_d | the right-hand side of the equation located on the device(s) |
| [in] | data_d | the data points used in the dimensional reduction located on the device(s) |
| [in] | add | denotes whether the values are added or subtracted from the result vector |
| [in] | QA_cost | a value used in the dimensional reduction |
| [in] | num_data_points_padded | the number of data points after the padding has been applied |
| [in] | num_features | number of features used for the calculation in the device |
|
protectedpure virtualinherited |
Run the device kernel the calculate the w vector used to speed up the prediction when using the linear kernel function.
| [in] | device | the device ID denoting the device on which the kernel should be executed |
| [in] | range | the execution range used to launch the |
| [out] | w_d | the w vector to fill, used to speed up the prediction when using the linear kernel located on the device(s) |
| [in] | alpha_d | the previously calculated weight for each data point located on the device(s) |
| [in] | data_d | the data points used in the dimensional reduction located on the device(s) |
| [in] | data_last_d | the last data point of the data set located on the device(s) |
| [in] | num_data_points | the number of data points |
| [in] | num_features | number of features used for the calculation on the device |
|
protectedpure virtualinherited |
Run the device kernel the calculate the w vector used to speed up the prediction when using the linear kernel function.
| [in] | device | the device ID denoting the device on which the kernel should be executed |
| [in] | range | the execution range used to launch the |
| [out] | w_d | the w vector to fill, used to speed up the prediction when using the linear kernel located on the device(s) |
| [in] | alpha_d | the previously calculated weight for each data point located on the device(s) |
| [in] | data_d | the data points used in the dimensional reduction located on the device(s) |
| [in] | data_last_d | the last data point of the data set located on the device(s) |
| [in] | num_data_points | the number of data points |
| [in] | num_features | number of features used for the calculation on the device |
|
protectedpure virtualinherited |
Run the device kernel (only on the first device) to predict the new data points point_d.
| [in] | range | the execution range used to launch the kernel |
| [in] | params | the SVM parameter used (e.g., kernel_type) |
| [out] | out_d | the calculated prediction |
| [in] | alpha_d | the previously calculated weight for each data point located on the device(s) |
| [in] | point_d | the data points to predict located on the device(s) |
| [in] | data_d | the data points used in the dimensional reduction located on the device(s) |
| [in] | data_last_d | the last data point of the data set located on the device(s) |
| [in] | num_support_vectors | the number of support vectors |
| [in] | num_predict_points | the number of data points to predict |
| [in] | num_features | number of features used for the calculation on the device |
|
protectedpure virtualinherited |
Run the device kernel (only on the first device) to predict the new data points point_d.
| [in] | range | the execution range used to launch the kernel |
| [in] | params | the SVM parameter used (e.g., kernel_type) |
| [out] | out_d | the calculated prediction |
| [in] | alpha_d | the previously calculated weight for each data point located on the device(s) |
| [in] | point_d | the data points to predict located on the device(s) |
| [in] | data_d | the data points used in the dimensional reduction located on the device(s) |
| [in] | data_last_d | the last data point of the data set located on the device(s) |
| [in] | num_support_vectors | the number of support vectors |
| [in] | num_predict_points | the number of data points to predict |
| [in] | num_features | number of features used for the calculation on the device |
|
inlinenoexceptinherited |
Return the target platform (i.e, CPU or GPU including the vendor) this SVM runs on.
[[nodiscard]])
|
inlinenoexceptinherited |
Return the currently used SVM parameter.
[[nodiscard]])
|
inlinenoexceptinherited |
Override the old SVM parameter with the new plssvm::parameter params.
| [in] | params | the new SVM parameter to use |
|
inherited |
Override the old SVM parameter with the new ones given as named parameters in named_args.
| Args | the type of the named-parameters |
| [in] | named_args | the potential named-parameters |
|
inherited |
Fit a model using the current SVM on the data.
| real_type | the type of the data (float or double) |
| label_type | the type of the label (an arithmetic type or std::string) |
| Args | the type of the potential additional parameters |
| [in] | data | the data used to train the SVM model |
| [in] | named_args | the potential additional parameters (epsilon and/or max_iter) |
| plssvm::invalid_parameter_exception | if the provided value for epsilon is greater or equal than zero |
| plssvm::invlaid_parameter_exception | if the provided maximum number of iterations is less or equal than zero |
| plssvm::invalid_parameter_exception | if the training data does not include labels |
| plssvm::exception | any exception thrown in the respective backend's implementation of plssvm::csvm::solve_system_of_linear_equations |
[[nodiscard]])
|
inherited |
Predict the labels for the data set using the model.
| real_type | the type of the data (float or double) |
| label_type | the type of the label (an arithmetic type or std::string) |
| [in] | model | a previously learned model |
| [in] | data | the data to predict the labels for |
| plssvm::invalid_parameter_exception | if the number of features in the model's support vectors don't match the number of features in the data set |
| plssvm::exception | any exception thrown in the respective backend's implementation of plssvm::csvm::predict_values |
[[nodiscard]])
|
inherited |
Calculate the accuracy of the model.
| real_type | the type of the data (float or double) |
| label_type | the type of the label (an arithmetic type or std::string) |
| [in] | model | a previously learned model |
| plssvm::exception | any exception thrown in the respective backend's implementation of plssvm::csvm::predict_values |
[[nodiscard]])
|
inherited |
Calculate the accuracy of the labeled data set using the model.
| real_type | the type of the data (float or double) |
| label_type | the type of the label (an arithmetic type or std::string) |
| [in] | model | a previously learned model |
| [in] | data | the labeled data set to score |
| plssvm::invalid_parameter_exception | if the data to score has no labels |
| plssvm::invalid_parameter_exception | if the number of features in the model's support vectors don't match the number of features in the data set |
| plssvm::exception | any exception thrown in the respective backend's implementation of plssvm::csvm::predict_values |
data ([[nodiscard]])
|
inlineprivateinherited |
Perform some sanity checks on the passed SVM parameters.
| plssvm::invalid_parameter_exception | if the kernel function is invalid |
| plssvm::invalid_parameter_exception | if the gamma value for the polynomial or radial basis function kernel is not greater than zero |